


Here on FSIblog, queries about Software Dowsstrike2045 Python come in through Aqib’s intake regularly. A developer encounters the exact string in a job description, a client brief, an internal repository, or an AI-generated deliverable, and the open web has nothing to say about it. The instinct is to assume the search query is wrong. In our team’s experience at Programmatic LLC, the search query is almost never wrong. The term itself is the problem, and identifying what kind of problem it is shapes the entire response.
Where the Term Software Dowsstrike2045 Python Usually Originates
Three sources account for almost every instance our backend developers have traced.
- Internal company codename. Engineering organizations in fintech, infrastructure consultancies, and defense-adjacent SaaS routinely assign internal codenames to deployment profiles, hardening configurations, or proprietary frameworks. The naming pattern of Software Dowsstrike2045 a compound word followed by a forward-dated year suffix fits that convention closely. If the term appeared inside an NDA-covered repository, a private Confluence space, or a client engagement scoped to a single organization, this is the most probable explanation. There is no public documentation because there is no public artifact.
- Transcription artifact. “Dowsstrike” is not a standard English compound, and the construction reads like a misheard or auto-corrected version of something else CrowdStrike, Downstrike, DowJones Strike, or a vendor product name that was hand-typed without verification. CrowdStrike, for example, publishes Python SDKs for the Falcon platform, and a misheard reference to a roadmap item tagged with a future year would plausibly land in notes as “Dowsstrike2045.” The 2045 suffix is itself a clue: forward-dated years in software naming typically indicate either a compliance target year or a vendor roadmap horizon.


- AI-generated hallucination. A junior staffer feeds a brief into a language model, the model invents a plausible-sounding framework name that does not exist, and the term flows downstream into deliverables, job specs, and internal documents without anyone verifying the underlying artifact. When Software Dowsstrike2045 Python arrives via a client brief or a recruiter’s job description, this is worth checking before any architecture work begins.
Before treating the phrase as a deployment target, ask the source for a repository URL, a PyPI page, a vendor link, or an internal wiki entry. If none exists, the term is not a real architectural target and no amount of deployment work will produce a meaningful result against it.
What Resilient Software Dowsstrike2045 Python Deployment Architecture Actually Requires
Setting the unverified term aside, the architectural principles for resilient Python deployments are well-defined and stack-agnostic. The patterns below are what our backend team applies on live client deployments at Programmatic LLC, and they are the substance behind any credible deployment hardening profile regardless of what name sits on top of it.
Process-Level Resilience Before Infrastructure-Level Resilience
The most common failure mode in Python deployments is reaching for Kubernetes, multi-region failover, and chaos engineering tooling before stabilizing a single Gunicorn process. Resilience starts at the worker boundary.
A production-grade Gunicorn invocation looks like this:
bash
gunicorn app:app \
--workers 4 \
--worker-class uvicorn.workers.UvicornWorker \
--timeout 30 \
--graceful-timeout 30 \
--max-requests 1000 \
--max-requests-jitter 50 \
--preloadThe settings that matter most:
--max-requests 1000 --max-requests-jitter 50is the single most underused pair in Python deployment configuration. It forces worker recycling before slow memory leaks compound into outages. Application that runs cleanly for three days will frequently begin OOM-killing on day five without this flag.--preloadloads the application before forking workers, which surfaces import-time failures at startup instead of at the first inbound request, and allows read-only memory pages to be shared across workers. On Django and Flask applications with heavy import graphs, this cuts resident memory per worker by 20 to 40 percent.
Connection Pooling in Software Dowsstrike2045 Python Deployments
When a Python deployment falls over under load, CPU is almost never the cause. Connection exhaustion is Postgres connections, Redis connections, outbound HTTP connections to third-party APIs. The deployment looks healthy on requests-per-second dashboards and fails on dependency metrics that nobody instrumented.
For Postgres with SQLAlchemy, a realistic production pool configuration is:
python
engine = create_engine(
DATABASE_URL,
pool_size=10,
max_overflow=20,
pool_pre_ping=True,
pool_recycle=1800,
)Two settings carry the resilience weight here:
pool_pre_ping=Trueprevents the most common production incident our Python developers see queries on: a connection that the database server has already closed but that the pool still considers alive. Without pre-ping, the first request to grab that connection raisesOperationalError: server closed the connection unexpectedlyand the end user receives a 500. With pre-ping enabled, SQLAlchemy issues a lightweightSELECT 1before handing the connection to application code and silently replaces dead connections.pool_recycle=1800is the companion setting. Managed Postgres providers RDS, Cloud SQL, Supabase have idle connection timeouts in the one-hour range. Force-recycling pool connections every 30 minutes keeps the application safely below that ceiling.
Health Checks That Actually Verify Health
The most frequently mis-implemented pattern in Python deployments is the /health endpoint that returns {"status": "ok"} unconditionally and gets wired into the load balancer. The container reports healthy while the database is unreachable. The load balancer keeps routing traffic. Users see errors.
A health check that means something has to verify the dependencies the application actually requires:
python
@app.get("/health")
async def health():
checks = {}
try:
await db.execute("SELECT 1")
checks["db"] = "ok"
except Exception as e:
checks["db"] = f"fail: {type(e).__name__}"
try:
await redis.ping()
checks["redis"] = "ok"
except Exception as e:
checks["redis"] = f"fail: {type(e).__name__}"
healthy = all(v == "ok" for v in checks.values())
return JSONResponse(
content={"checks": checks},
status_code=200 if healthy else 503,
)Two points on this pattern:
- Separate liveness from readiness. Liveness checks (is the process running?) and readiness checks (can the process serve traffic?) need to be different endpoints. Kubernetes distinguishes them because liveness failures trigger restarts while readiness failures only remove the pod from the load balancer rotation. Conflating them produces restart loops when a downstream dependency hiccups.
- Cache dependency check results for two to five seconds. A health endpoint hit by a load balancer every second that itself queries Postgres every second adds measurable load on a busy deployment, and that load shows up as latency on real user traffic.
Graceful Shutdown in Software Dowsstrike2045 Python Workloads
When an orchestrator sends SIGTERM, the Python process has a finite window 30 seconds on Kubernetes by default to complete in-flight work and exit. Most deployments either ignore SIGTERM and get SIGKILLed, which drops in-flight requests, or handle it incompletely.
Gunicorn handles HTTP request draining correctly out of the box when --graceful-timeout matches the orchestrator’s grace period. The failure point is background work Celery workers, asyncio tasks spawned with create_task, long-running data processing that does not respect the shutdown signal.
The pattern that works:
python
import signal
import asyncio
shutdown_event = asyncio.Event()
def handle_shutdown(signum, frame):
shutdown_event.set()
signal.signal(signal.SIGTERM, handle_shutdown)
signal.signal(signal.SIGINT, handle_shutdown)
async def background_worker():
while not shutdown_event.is_set():
try:
await asyncio.wait_for(do_work(), timeout=5.0)
except asyncio.TimeoutError:
continueThe wait_for with timeout is the part developers most often skip. Without it, a long-running do_work() call cannot be interrupted by the shutdown signal, and the container is SIGKILLed mid-task regardless of how carefully the signal handler was written.
Observability Before Resilience Engineering
Architectural resilience cannot be verified without observability instrumented first. Before adding circuit breakers, retry logic, or fallback paths, the deployment needs three things measured:

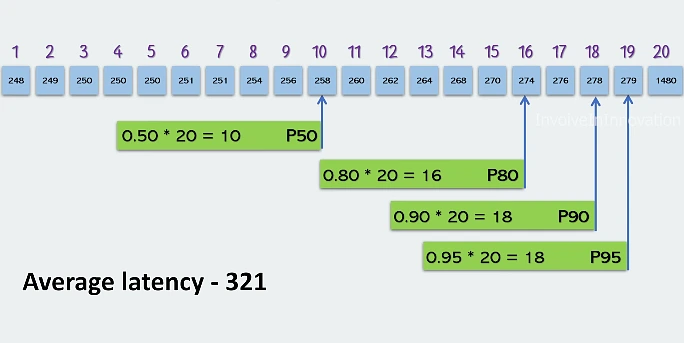
- Request duration histograms at p50, p80, p90, and p995not averages, which hide tail latency.
- Error rates broken down by endpoint aggregate error rate hides which routes are degraded.
- Dependency call latencies Postgres, Redis, outbound HTTP, each tracked separately.
OpenTelemetry’s Python SDK covers this for most stacks, and the auto-instrumentation packages opentelemetry-instrumentation-flask, -fastapi, -django, -sqlalchemy, -requests capture the majority of what is needed without application code changes.
Every resilience pattern added to a deployment needs to be measurable. Retries, circuit breakers, bulkheads, fallback paths each adds complexity, and unmeasured complexity is itself a source of failure.
Resolving the Software Dowsstrike2045 Python Term Before Building Against It
The actionable next step depends on where the term originated:
- Internal source. Request the repository, package name, internal wiki page, or build artifact that defines Software Dowsstrike2045 Python. If no such artifact can be produced, the term is not a real target and architecture work against it produces nothing usable.
- Client brief, job description, or AI-generated content. Treat the appearance of the term as a flag to verify the rest of the source document. A fabricated technical term is rarely the only fabricated element in a brief.
- Deployment log, error message, or CI output. The term is more likely a real internal identifier possibly a service name, a build tag, or a deployment profile name and the resolution path is to search the infrastructure-as-code repositories and CI configuration for the exact string.
The deployment architecture patterns in the sections above hold regardless of what framework name or internal codename sits on top of them. Resilient Python deployment is a property of how processes are configured, how connections are pooled, how shutdown is handled, and how the system is observed. It is not a property of which named framework appears in the requirements file.